
Online Payments Fraud Detection with Machine Learning
Started: 2025-11-28
About this project
Online Payments Fraud Detection with Machine Learning
Author: Leon Motaung
Environment: Python, Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn, Plotly
Project Overview
This project focuses on detecting fraudulent online payment transactions using machine learning.
The dataset contains 284,808 transactions with 30 anonymized features (V1–V28), plus
Amount, Time, and Class where 1 = fraud and 0 = normal.
After cleaning, preprocessing, and feature engineering, the final dataset was saved as creditcard_final.csv.
Data Source
The original dataset is publicly available on Figshare: Credit Card Fraud Detection Dataset (external link).
Data Preprocessing
- Handled missing values
- Corrected data types
- Encoded categorical features (none present)
- Scaled
AmountandTimefeatures - Removed outliers using IQR
- Added feature:
scaled_amount(log-transformed) - Saved cleaned dataset as
creditcard_final.csv
Data Visualization
The following visualizations helped understand feature distributions and class imbalance:
- Boxplots: Detect outliers and feature spread.
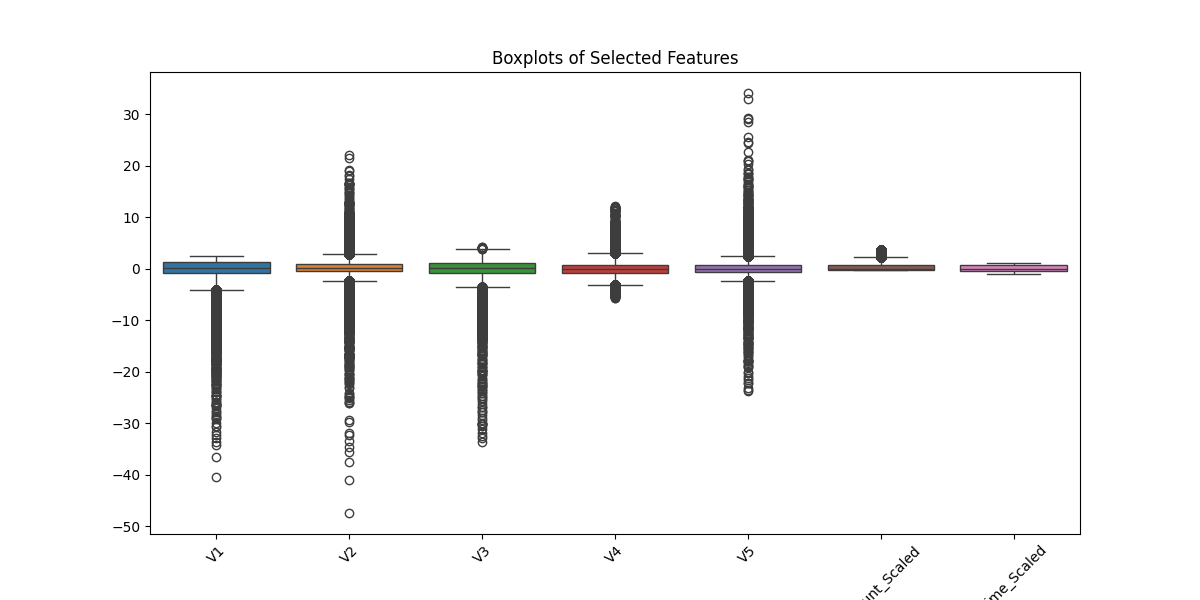
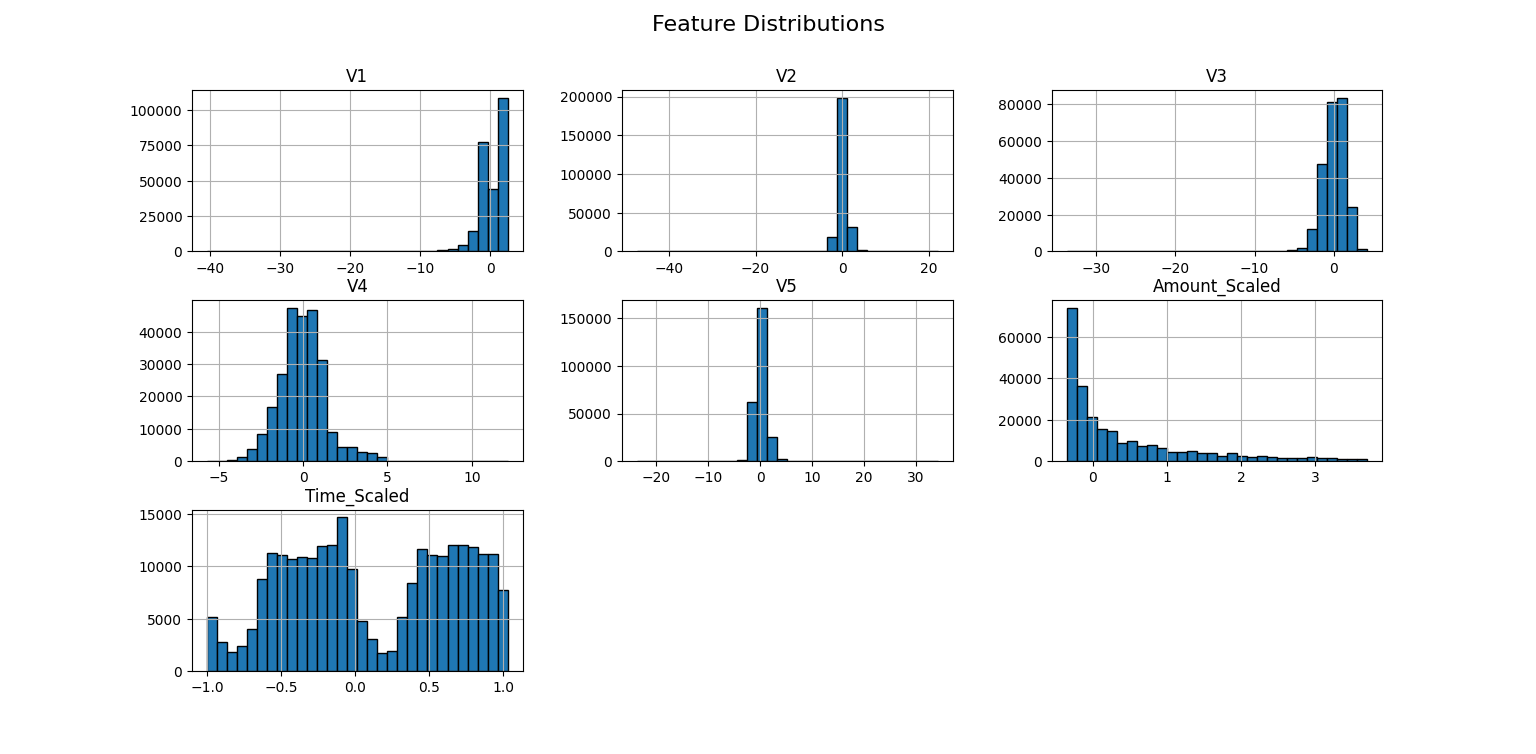
- Histograms & Feature Distributions: Visualizing scaled features.
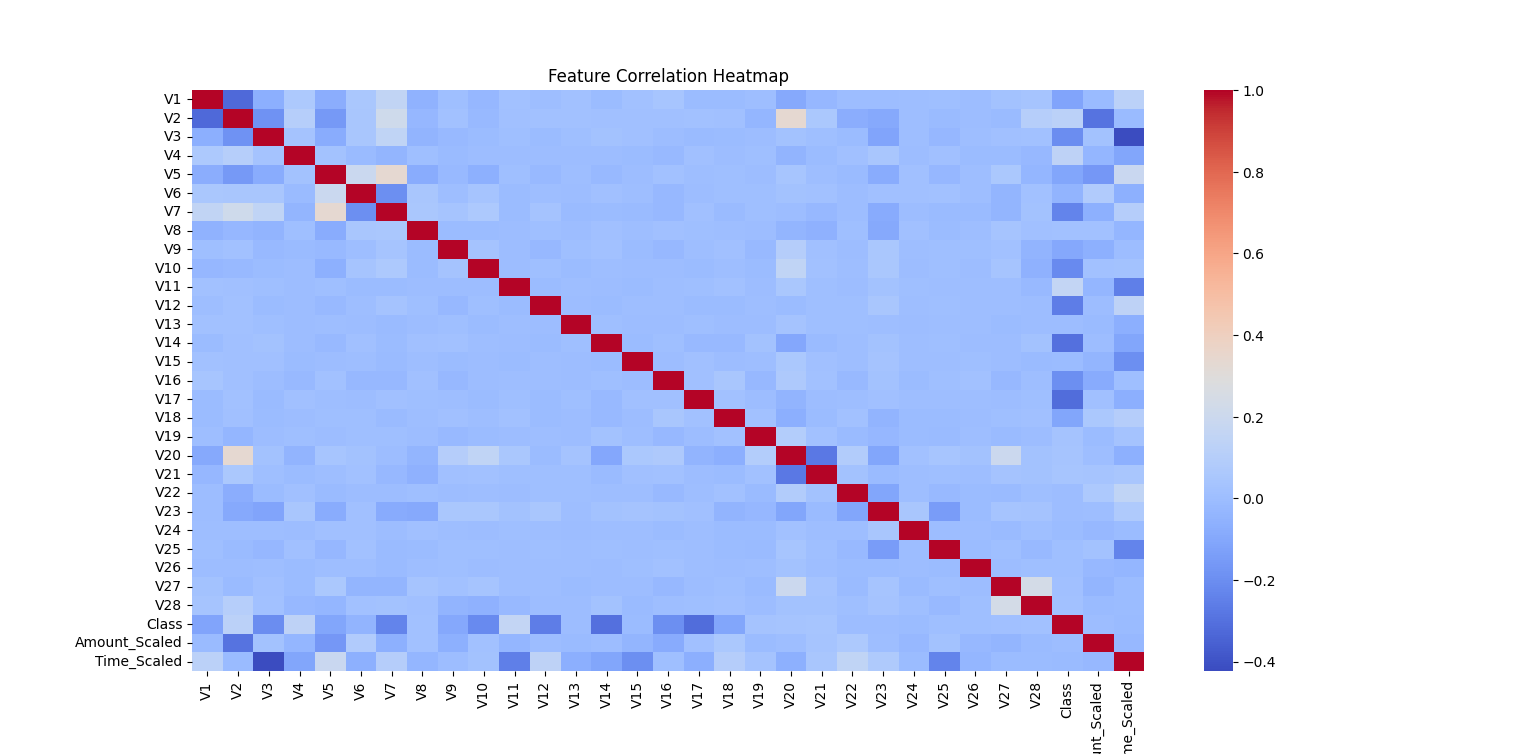
- Correlation Heatmap: Shows relationships between features and the target label.
- Scatterplot: Patterns between
V2andV4.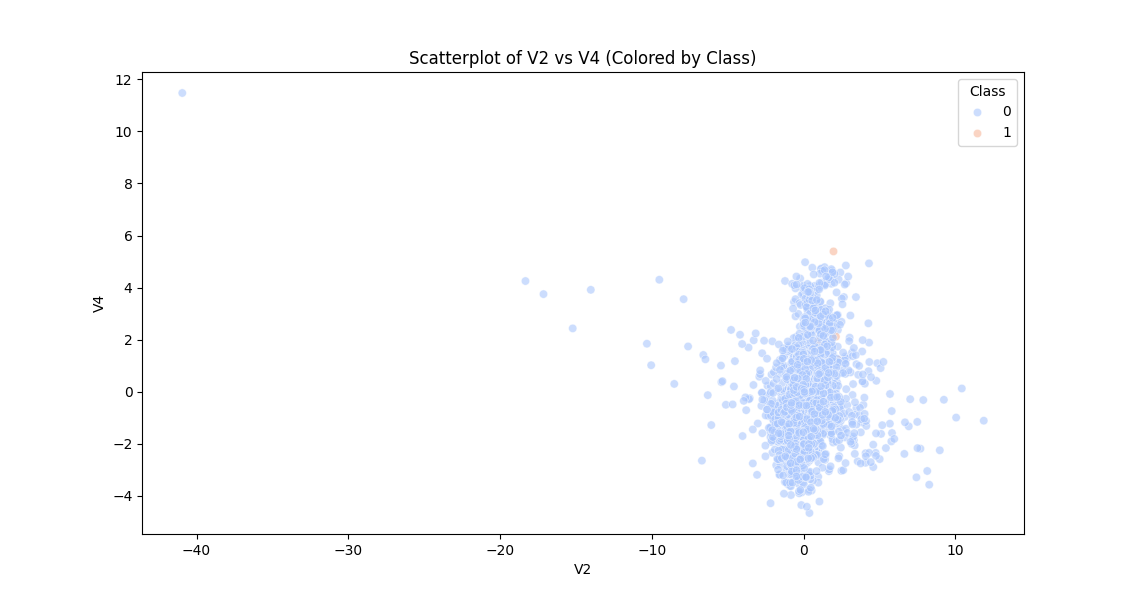
Baseline Model Evaluation
| Model | Accuracy | Precision | Recall | F1-score | Notes |
|---|---|---|---|---|---|
| Logistic Regression | 0.9768 | 0.0577 | 0.8929 | 0.1083 | Simple baseline model |
| Decision Tree | 0.9993 | 0.8478 | 0.6964 | 0.7647 | Shows feature importance |
| K-Nearest Neighbors (KNN) | 0.9995 | 0.9744 | 0.6786 | 0.8000 | Best with small datasets |
Note: Recall and F1-score are more important than Accuracy due to class imbalance.
Next Steps
- Apply SMOTE / undersampling for class imbalance
- Train advanced models: XGBoost, LightGBM
- Evaluate with Precision, Recall, F1-score, ROC-AUC
- Deploy via Flask or Streamlit for real-time fraud detection
Project Structure
app.py– Training & prediction scriptdraw.py– Visualization scriptcreditcard_final.csv– Processed dataset- Visuals – Boxplots, scatterplots, heatmaps, charts
This project gave me practical experience in preprocessing, visualization, and evaluating machine learning models for real-world fraud detection tasks.